
Haven’t you always wished for a tool that could tell you whether a sentence was positive or negative?
...No?
Well me neither.
But, I stumbled across Yelp’s review database and thought it would be fun to try a bit of natural language processing. So here you go, the sentiment classifier that you never knew you wanted:
(Direct link to web app)
Since the model was trained on Yelp reviews, it seems to work better on sentences like:
“This pizza tastes terrible.”
Rather than something like:
“The long night is coming, and the dead come with it.”
The RNN model appears more accurate than logistic regression, at least in my testing.
WORD INSIGHTS
Before getting into the nitty-gritty details of the models, here are some nice visuals on word insights to get you (dear reader) to keep scrolling...
LOGISTIC REGRESSION WORD IMPORTANCES
Words with high feature importance in the logistic regression model are plotted below - no real surprises here.

RNN LEARNED WORD RELATIONSHIPS
The interactive 3D plot below shows the embedding weights learned by the RNN model for a sample of words (dimensionality is reduced with t-SNE so they can be visualized). Words that are close distance in the plot are considered close by the model.
Click (or tap) and drag to spin.
You can see that the model learned a bunch of relationships that make logical sense:
attorney and lawyer are really close
drink, music, dance, bar are all close together
cat and dog are neighbors, and disturbingly close to beef and pork
You’ve got nice, good, polite in a cluster, and bad, loud, rude, no, parking in another cluster
This one triggered me: crowded, gym
This was my favorite: toro, sake, and expensive
More details on the models below - fair warning, there aren’t any more cool graphs.
THE MODELS
Logistic Regression Classifier
The first step in any sentiment analysis is to translate sentences into numbers so that the “machine” can do calculations. For the logistic regression model, I used the term frequency-inverse document frequency (tf-idf) method to assign numeric weights to the words.
Term frequency: how often the term appears in the review
Document frequency: how many reviews contain the term
A high weight is assigned if a word has a high term frequency (appears frequently in the review) and low document frequency (is relatively rare in other reviews).
After transforming the review text into a dataset of tf-idf weights, I added labels (3 stars or fewer = “negative”, 4 or 5 stars = “positive”) and fed the dataset into a logistic regression model.
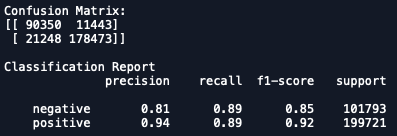
15K word vocabulary, C=0.1
The model achieved 89% recall on both negative and positive reviews on the test set, but had much better precision on positive reviews. Tuning C (inverse regularization parameter) didn’t help much. Adding words to the vocabulary didn’t help either, but restricting the vocabulary to 10K words produced marginally worse results.
Recurrent Neural Network Classifier
Key differences between using a recurrent neural network vs logistic regression (besides a much cooler name):
Uses SEQUENCES of words rather than simple term frequency (eg. “not bad” instead of “not” and “bad” separately)
WAY more computationally expensive
Just like logistic regression, we need weights for each word - but in this case the weights are learned as part of the larger training process. Weights are first initialized randomly, then passed forward through the model, then passed back with the gradients of the loss function, thus gradually learning the optimal embedding weights with more iterations. Word sequence also comes into play - as each word passes through the model, it takes input information from words that came before it.
To avoid punishing my MacBook GPU, I ended up going the cloud GPU route with Kaggle. Due to the 9-hour kernel run-time limit, I had to trade off the number of reviews in the dataset with the training batch size (with 750K records and batch size of 1024, you need to pass 733 batches through the network per epoch, for 100 epochs). I found that using fewer records with a smaller batch size produced better results.
Results below (0=negative, 1=positive):

750K reviews, 1024 batch size, 100 epochs

100k reviews, 128 batch size, 100 epochs

50K reviews, 64 batch size, 100 epochs
The RNN model with 50K reviews and batch size of 64 achieved better precision than the logistic regression model for negative reviews, and was comparable everywhere else.